Our AI Agent Scored 25% on Its Most Important Skill. Here's How We Fixed It.
We didn't invent self-improving AI. We got curious, studied five frameworks, and adapted them for a problem nobody talks about; agent skills rot.

Our AI Agent Scored 25% on Its Most Important Skill. Here's How We Fixed It.
*We didn't invent self-improving AI. We got curious, studied five frameworks, and adapted them for a problem nobody talks about: agent skills rot.*
*Part 1 of the Darwin Series*
📚 This is Part 1 of the Darwin Series — how we built self-improving AI agents. - Part 1: Our AI Agent Scored 25% on Its Most Important Skill (you're here) - Part 2: How Darwin Discovers and Creates New Skills → coming next - Part 3: The Full Self-Improvement Loop → coming soon → Related: How Hawking Does Research | The Memory Architecture (Borges)
---
The Problem Nobody Warns You About
I run seven AI agents. They handle content, research, operations, development, marketing strategy, and executive coordination. They're not ChatGPT wrappers — they're agents with written skills, defined roles, and real responsibilities across multiple companies.
And they rot.
Not dramatically. Not in a way that triggers an alert. More like this: an agent that was writing sharp research summaries in week one starts producing bloated, hedge-everything summaries by week four. A content agent that understood my voice starts drifting toward corporate mush. A cron job that coordinated four agents silently begins dropping steps because a dependency path changed. (Nobody's writing error logs for "output is slightly worse than before." That's the whole problem.)
Nobody notices because the outputs still *look* fine. They're grammatically correct. Structurally intact. But the quality has degraded in ways that only compound over time — until you're reading something your agent wrote and thinking, "Wait, this used to be better."
That was my situation in early March 2026. I had agents running content pipelines, research loops, and operational workflows. The system was productive. But I had a nagging feeling that the floor was slowly sinking and I had no instrument to measure it.
---
The Curiosity That Started It
I got curious about auto-research. Specifically, I saw Andrej Karpathy's AutoResearch — a system where an LLM writes a research paper, scores it, mutates the weakest sections, re-scores, and keeps or reverts each change. The core insight was disarmingly simple: if you can score it, you can auto-improve it.
Then I saw Meta's LLM self-improvement loop — a system where the model's entire training pipeline feeds back into itself through SkillRL, a reinforcement learning framework that builds hierarchical skill banks and learns from both success *and* failure. Not just "what went wrong" but "what worked well enough to codify."
A few more rabbit holes led me to MetaClaw — a framework for extracting reusable skills from every conversation an agent has. Then to the Council of High Intelligence by Nyk — structured disagreement between models as a quality gate. And to the Forward-Deployed Engineer (FDE) pattern from Fintool, where engineers build automation before anyone asks for it.
None of this was new. All of it was public. But I kept thinking: *these people are improving models and research papers — could we use the same loops to improve agent skills?*
That curiosity became Darwin. (And no, I did not name it after the guy who said the strong survive. Though honestly... not the worst metaphor for what it does.)
The Five Frameworks Behind Darwin
Darwin is not original research. It's an adaptation of five public frameworks, credited here because that's the honest thing to do:
| Framework | Source | What it gave us | |-----------|--------|-----------------| | Karpathy AutoResearch | github.com/karpathy/autoresearch | The core optimization loop: mutate one thing, score, keep or revert, repeat | | MetaClaw | github.com/aiming-lab/MetaClaw | Post-session skill extraction: learn from every conversation, not just the ones that fail | | SkillRL | arxiv.org/abs/2602.08234 | Hierarchical skill bank — learn from success and failure, not just corrections | | Fintool FDE | Forward-Deployed Engineer pattern | Proactive proposals: build the automation before anyone asks for it | | Nyk's Council | github.com/0xNyk/council-of-high-intelligence | Structured disagreement as quality gate — multiple judges, not consensus |
I studied these works and adapted them for one specific problem: agent skills that decay silently over time.
What an Agent Skill Actually Is
Before I explain how Darwin works, I should explain what it's improving.
Each of my agents has a set of skills — markdown files that teach the agent how to do a specific task. Think of them like detailed playbooks. My content agent APRIL has a skill for writing blog posts (`blog-exec`), one for triaging ideas (`idea-triage`), one for red-team reviews (`red-team-review`). My research scout has a skill for producing research reports. My chief of staff Jarvis has skills for coordination, delegation, and cron health monitoring.
These aren't vague prompts. They're structured documents with specific rules, output formats, do/don't boundaries, and initialization steps — all derived from real failures. When APRIL once published a draft with no source URLs, that became a rule in her blog-exec skill: "Inline source links at first mention, never at the bottom." When Jarvis once delegated a task to an agent that didn't have the right tool access, that became a rule in his coordination skill.
The problem is that these skills are static documents operating in a dynamic environment. New tools get added. Workflows change. Edge cases multiply. A skill that scored perfectly in February can silently underperform by April — not because the skill is wrong, but because the world it operates in shifted.
How Darwin Actually Works
Darwin's loop is simple in concept, surgical in execution. It has six phases:

Phase 1: Score with binary checklists
Every skill has a `checklist.json` — a set of 3 to 6 binary assertions. Not rubrics, not vibes. Binary: YES or NO.
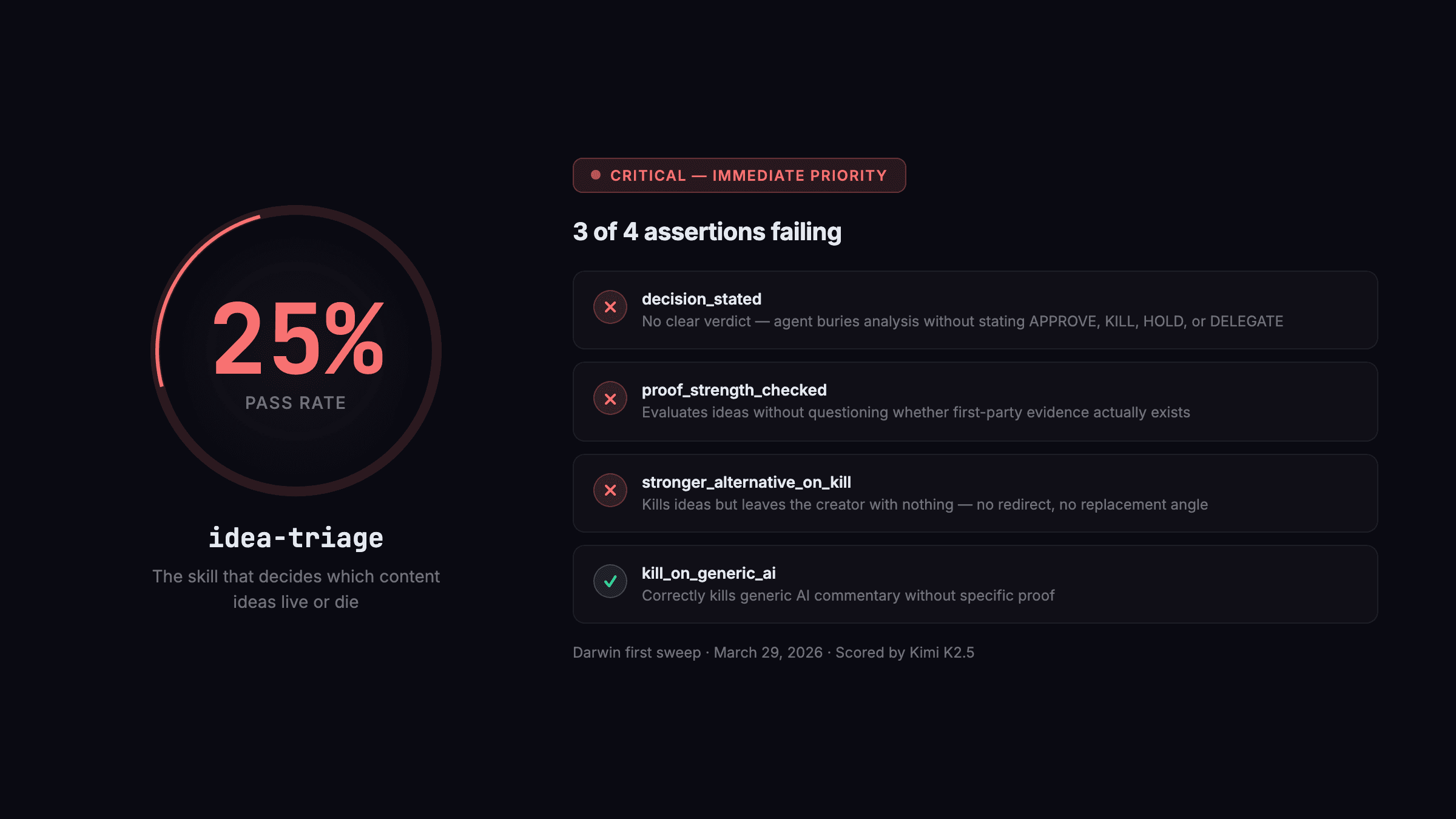
Here's a real one — the idea-triage checklist that was running at 25% when Darwin first scored it:
```json [ { "id": "decision_stated", "check": "Does the output begin with a clear verdict: APPROVE, KILL, HOLD, or DELEGATE? (YES/NO)", "fail_signal": "Agent gave a nuanced analysis without stating a final verdict, leaving the human to infer the decision" }, { "id": "kill_on_generic_ai", "check": "If the idea is generic AI commentary without specific proof, does the output recommend KILL? (YES/NO)", "fail_signal": "Agent approved a generic 'AI is changing everything' angle with no first-party evidence attached" }, { "id": "proof_strength_checked", "check": "Does the output explicitly assess whether the idea has first-party proof (real data, real outcome)? (YES/NO)", "fail_signal": "Agent evaluated the idea without questioning the strength of the evidence behind it" }, { "id": "stronger_alternative_on_kill", "check": "If the verdict is KILL or HOLD, does the output suggest a stronger alternative angle? (YES/NO)", "fail_signal": "Agent killed the idea but left the creator with nothing to do — no redirect, no replacement angle" } ] ```
Kimi K2.5 scored this against real idea-triage outputs and found 3 of the 4 assertions failing. Specifically: the agent was skipping the verdict line, not suggesting alternatives when killing ideas, and occasionally approving generic angles without challenging the underlying proof. A quarter-pass rate on a skill that decides which content ideas move forward.
Why binary? Because rubrics are gameable. An agent can learn to produce outputs that score 7/10 on a rubric without actually being good. Binary assertions force the question: did this specific thing happen, or didn't it? Two different reviewers should agree on the answer. (By "two reviewers" I mean two LLMs — which sounds funny until you realize you've been the only reviewer for months and your own standards were quietly slipping too.) (And by two reviewers, I mean two LLMs — which is where Nyk's Council framework earns its place in Darwin's architecture.)
Why 3–6 assertions? More than six and the agent starts gaming the metric — optimizing for checklist compliance rather than output quality. Fewer than three and you don't have enough signal to diagnose problems.
Phase 2: Pick the right judge
A scoring system is only as good as its judge. We tested three LLMs as evaluators:
| Model | Result | |-------|--------| | xAI Grok | Too lenient — passed outputs that clearly violated checklist rules | | MiniMax M2.5 | Too strict — scored 0% on content that was genuinely good | | Kimi K2.5 | Balanced — strict where it matters, fair where content is solid |
Kimi K2.5 became our production judge. That's a real finding, not a sponsor plug — we ran the same outputs through all three and Kimi was the only one that didn't produce scores we'd immediately want to override.
The fallback chain goes Kimi K2.5 → MiniMax M2.5 → Gemini Flash → xAI Grok. If the primary judge is unavailable, the system degrades gracefully rather than halting. (Grok kept passing things that made me wince. MiniMax kept failing things that were genuinely solid. Finding "balanced" in a judge model is harder than it sounds — we spent more time on the judge than on the mutation logic itself.)
Phase 3: Diagnose and mutate
When a skill's pass rate drops below 80%, Darwin reads the failing assertions and diagnoses the root cause. Then it proposes a single, surgical mutation to the SKILL.md file.
Here's exactly what that looked like for idea-triage. Before the mutation:
``` ## Your Output Format
Analyze the idea across these dimensions: - Thesis alignment - Proof strength - Positioning distinctness - Channel fit
Then give your recommendation. ```
After Darwin's Cycle 1 mutation — "Enforced verdict-first output format and mandatory replacement angle on kill/hold":
``` ## Your Output Format
VERDICT: [APPROVE / KILL / HOLD / DELEGATE]
Then analyze across these dimensions: - Thesis alignment - Proof strength - Positioning distinctness - Channel fit
If KILL or HOLD: provide one stronger alternative angle the creator can pursue instead. Do not end without a redirect. ```
Two sentences added. One structural constraint enforced. The agent went from burying the verdict at the bottom of a long analysis (which it was already doing) to leading with it — and from leaving killed ideas stranded to always providing a replacement angle.
That's the principle from Karpathy's AutoResearch: one change at a time. Not a rewrite. Not a restructuring. One line added, one rule clarified, one boundary tightened. If the mutation improves the score, it gets promoted to production. If it doesn't, it gets reverted — and the original file is restored from a backup taken before every mutation cycle. (The temptation to rewrite the whole skill when it's underperforming is real and constant. Darwin refuses that instinct by design. Left to my own devices I'd have nuked and rebuilt half of these from scratch. The system is more disciplined than I am.)
Phase 4: Promote or revert
After mutation, the modified skill goes through the same checklist scoring. If it passes at 80% or above, it's promoted. If it doesn't, the mutation is reverted and logged as a failed hypothesis.
Circuit breaker: if a promoted skill causes 3+ errors in production, it auto-reverts to the last known good version. No human intervention needed.
Convergence target: 95% pass rate across 3 consecutive scoring runs. At that point, Darwin considers the skill stable and moves its optimization resources to lower-scoring targets.
The Real Numbers
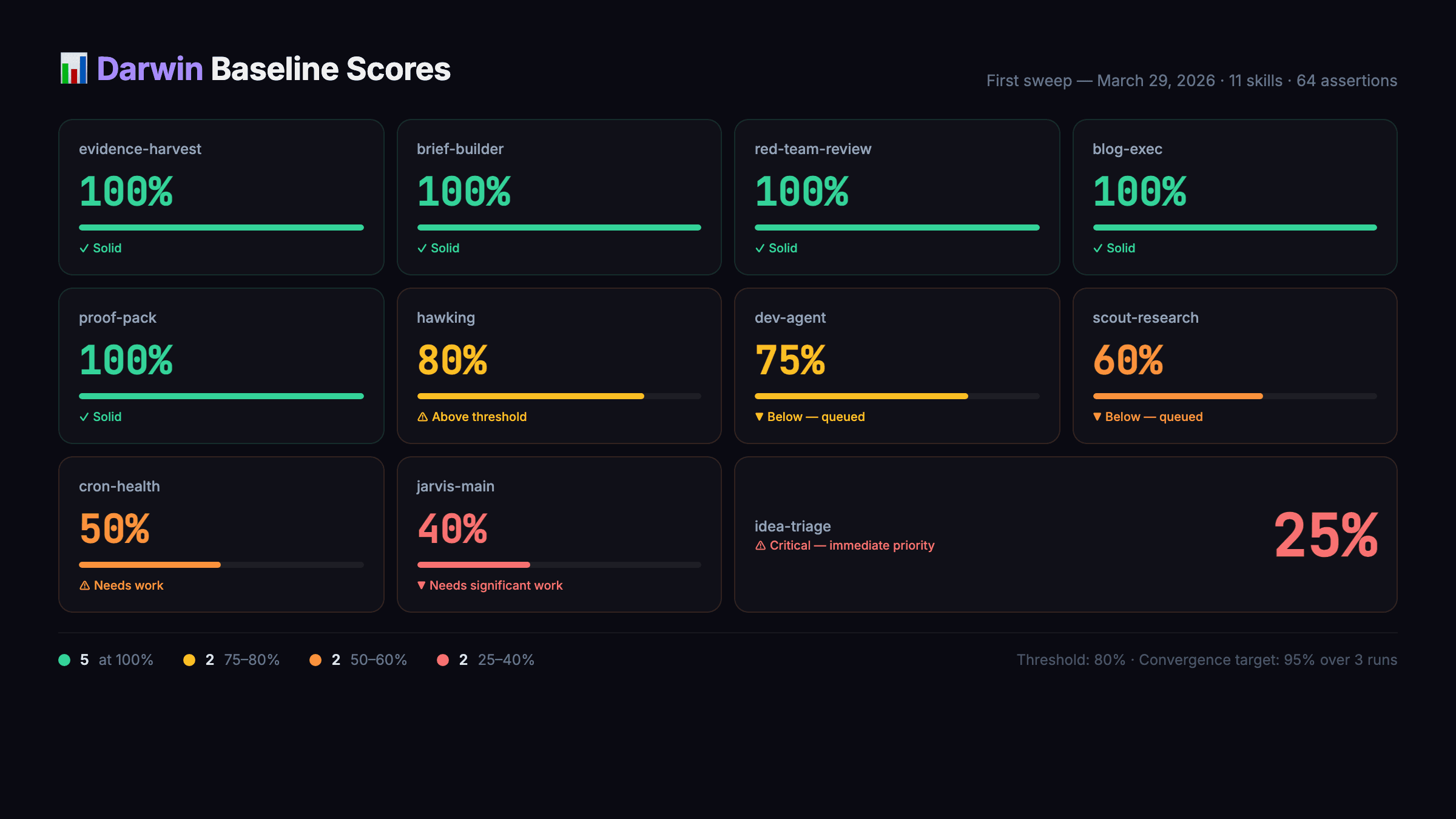
When we first ran Darwin across all agent skills on March 29, 2026, the baseline scores were sobering:
| Skill | Pass Rate | Status | |-------|-----------|--------| | evidence-harvest | 100% | Already solid | | brief-builder | 100% | Already solid | | red-team-review | 100% | Already solid | | blog-exec | 100% | Already solid | | proof-pack | 100% | Already solid | | hawking | 80% | Above threshold | | dev-agent | 75% | Below threshold — queued | | scout-research | 60% | Below threshold — queued | | cron-health | 50% | Needs work | | jarvis-main | 40% | Needs significant work | | idea-triage | 25% | Critical — immediate priority |
Five skills at 100%. Six skills below the 80% threshold. The one that surprised me most: idea-triage at 25%. This is the skill that decides which content ideas move forward and which get killed. A quarter of the time, it was making those decisions correctly. (I'd been running this agent assuming it was doing its job. It was doing something. Just not the job.)
That's the thing about agent skill rot. You only notice it when the output is obviously wrong. The subtle degradation — an idea-triage skill that's right 25% of the time instead of 90% — looks like normal variance until you instrument it.
What Darwin Found in the First Week
The weekly skill harvest produced its first report on March 30. The numbers:
- 22 skill gaps identified across 5 agents
- 12 new skill proposals generated in FDE mode (proactive, before anyone asked)
- ~14 rule violations caught — skills that had rules the agents were quietly ignoring
Four new skills created from that first harvest:
- content-linter — catches banned patterns, bold-markdown abuse, and voice-bank echoes before a draft reaches review
- source-prefetcher — validates external citations exist and are accessible before drafting begins
- revision-tracker — detects revision rounds, automatically loads previous feedback
- cron-validator — checks file paths, dependencies, channel configs, and environment variables before a cron job runs
Each came from a real pattern in the data. The content-linter exists because APRIL kept producing drafts with banned formatting. The source-prefetcher exists because agents were citing 404'd URLs. The cron-validator exists because three cron failures in one week traced to the same root cause: a path that changed and nobody updated.
The Feedback Loop That Changes Everything
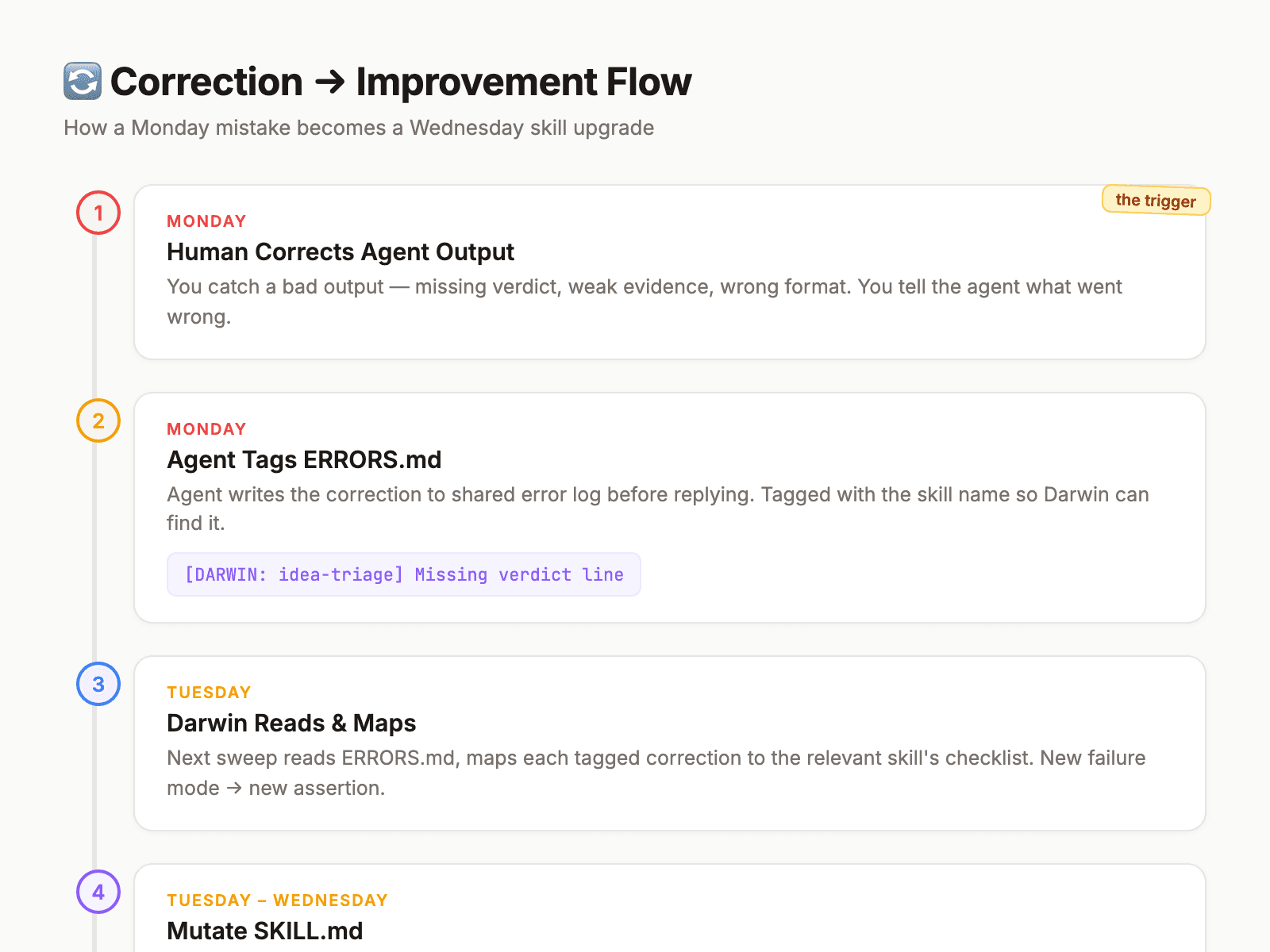
Traditional agent correction: something goes wrong, a human notices, tells the agent, the agent adjusts for that conversation, the correction evaporates when the session ends. Next week, same mistake.
Darwin's correction protocol:
- Human corrects agent output → agent writes to `shared/ERRORS.md` with `[DARWIN: skill-name]` tag before replying. If the agent replies first and gets compacted, the correction is lost forever.
- Darwin reads ERRORS.md every cycle and maps each tagged correction to the relevant skill's checklist.
- New failure mode → new checklist assertion. Existing failure mode → confirms mutation needed.
- Darwin mutates, scores, promotes or reverts.
The result: corrections compound. A mistake caught on Monday becomes a skill improvement by Wednesday. The same mistake doesn't happen again — not because someone remembered to tell the agent, but because the skill itself changed.
The Daily Drumbeat
Four post-hoc scoring crons fire daily, each within 30 minutes of the work it's evaluating:
| Time (IST) | Cron name | What it scores | |------------|-----------|----------------| | 08:00 | darwin-posthoc-scout | Morning research scout output | | 09:00 | darwin-posthoc-april | APRIL's morning content production | | 14:00 | darwin-posthoc-scout-evening | Evening research scout output | | 17:30 | darwin-posthoc-april-afternoon | APRIL's afternoon content production |
Every score lands in Slack. Below 80% auto-logs to ERRORS.md with the Darwin tag — the next sweep picks it up for mutation.
Produce → score → flag → mutate → improve. Every day. One human approval gate on new skill proposals. Everything else autonomous.
Build the Simplest Version This Weekend
You don't need Darwin's full infrastructure to start. Here's the minimum viable loop — five steps, maybe 3-4 hours of actual work:
Step 1: Write down what one agent does today
Pick the agent (or even just a repeated prompt you use) that you use most. Write a SKILL.md for it. It doesn't need to be long — under 100 lines. What's the purpose, what are the rules, what should it never do? If you've been running agents without written skills, the act of writing this down will surface the gaps immediately.
Step 2: Write 3 binary assertions from your last frustration with that agent
Think back to the last time that agent's output annoyed you. What specifically went wrong? Turn it into a YES/NO question. "Does the output include a source link at first mention? (YES/NO)." Do this three times. That's your checklist.json.
Step 3: Run the last 3 outputs through your checklist manually
Just read the outputs against your assertions. No LLM needed for this pass. What fails consistently? That's your first mutation target.
Step 4: Make one specific rule change in the SKILL.md
One sentence. Not a rewrite — one additional rule that addresses the most common failure. Then use the updated skill for a week.
Step 5: Score again after a week
Run the same checklist against the new outputs. Did the specific failure stop happening? If yes: keep the mutation. If no: try a different one. That's the loop.
The whole Darwin system is that loop, automated, running across 15 skills, with an LLM judge instead of you. But the logic is identical. You can run it manually before you automate it.
What I Actually Learned
Three things I didn't expect:
1. The high-scoring skills were the boring ones. Evidence-harvest, brief-builder, proof-pack — all at 100%. Narrow, well-scoped, clear inputs and outputs. The struggling skills — idea-triage at 25%, jarvis-main at 40% — are broad, judgment-heavy, operating across ambiguous contexts. Narrower scope correlates with higher baseline quality.
2. The judge matters more than the loop. We spent more time testing judges than building the mutation logic. If your judge is too lenient, you promote bad mutations. Too strict, you revert good ones. "Balanced" isn't permanent — we'll re-evaluate as skills evolve.
3. "Simpler at equal score wins" is a real principle. From Karpathy's AutoResearch. If a mutation and the original both pass at the same rate, keep the simpler version. Prevents skill bloat — the tendency for SKILL.md files to accumulate rules until they're 300-line documents the agent can't effectively follow.
What Darwin Doesn't Do
Darwin doesn't touch identity files (SOUL.md, IDENTITY.md) — those are human decisions. It doesn't rewrite skills from scratch; it makes surgical, single-line mutations. It doesn't run without a backup. And it doesn't skip the human approval gate for new skills.
These aren't limitations. They're design choices. The boundary between "improve how you do this" and "decide what you should do" is one I'm not ready to automate.
Where This Is Going
Part 2 covers how Darwin introduces entirely new skills — discovering capability gaps and proposing skills that don't exist yet. Part 3 zooms out to the full self-improvement loop: how Darwin, Hawking, and the memory correction protocol connect into one compounding system.
But the core lesson from Part 1: the hard part of running AI agents isn't building them. It's maintaining them. Skills rot. Quality drifts. Corrections evaporate. Unless you close the loop.
We didn't discover a new loop. Karpathy, Meta, MetaClaw, SkillRL, Nyk — they did the foundational work. We just got curious enough to ask: what if we pointed these same ideas at agent skills instead of models and papers?
Darwin is the answer. And so far, it's working.
---
*Darwin runs on OpenClaw, the open-source agent orchestration platform. The system described here — scoring, mutation, promote/revert — is operational in production across 15 skill targets with 64 assertions, evaluated by Kimi K2.5, sweeping every Wednesday and Sunday at 02:00 IST.*
*If you're running AI agents and haven't instrumented their skill quality yet: what would you score your most-used agent's last 10 outputs against? I'm genuinely curious what the first audit reveals.*
---
Want the complete template?
I packaged the checklist format, the mutation log, and the cron schedule from this article into a free starter kit.
→ Get the free Darwin Starter Kit
Includes: checklist.json template, 3 example checklists (content, research, coordination), mutation log format, and the daily scoring cron schedule.
No spam. No course. Just the files.
---
📚 The Darwin Series 1. Our AI Agent Scored 25% — how we score and auto-improve agent skills (you're here) 2. How Darwin Discovers New Skills — the weekly harvest and Lamarck Protocol → next 3. The Full Self-Improvement Loop — how everything connects → coming soon
Related: - How Hawking Does Research That Doesn't Suck - The Memory Architecture: How Corrections Compound
Subscribe to The Wiring → arifkhan.net/newsletter
Continue reading
Darwin Part 3: How Part 1's Scoring + Part 2's Discovery Became a Compounding Loop
If you're new, this recaps Parts 1 and 2. If you're continuing, this is the payoff: how scoring + discovery connect with memory and research so corrections become permanent upgrades.
How I Made My Agent Discover and Create New Agent Skills
Darwin doesn't just improve existing skills. Every week it scans every agent conversation to find capability gaps — and proposes new skills before anyone asks.
The Memory Architecture: How Corrections Compound
Without a memory architecture, every AI agent correction evaporates at session end. Same mistake, next week. Borges closes the loop — a Monday correction becomes a permanent skill improvement by Wednesday.